WebRTC之Trendline滤波器
简述
在GCC(Google Congestion Control)拥塞控制算法中,包含了两种带宽估计算法,分别是基于延迟的带宽估计算法和基于丢包的带宽估计算法。
其中,基于延迟的带宽估计算法有新旧两个不同的实现版本,分别是:旧版使用基于接收端的Kalman滤波器带宽估计算法,新版使用基于发送端的Trendline滤波器带宽估计算法。
在WebRTC中,为了向前兼容仍保留了旧版的实现,且对于视频流会同时开启两种基于延迟的带宽估计算法。因此,如果存在视频流时,GCC还好收到从接收端返回的带宽估计值:REMB(Remote Estimated Maximum Bitrate)。GCC算法最终会选取这三个带宽估计值中的最小值作为当前的带宽估计值。
本文介绍的是新版基于延迟的带宽估计算法中的Trendline滤波器,可根据数据包的延迟梯度的变化预测带宽的变化趋势,以此为参考对当前码率进行相应的调整,进而获得更为接近真实情况的带宽估计值。
Trendline滤波器
在Trendline滤波器涉及了多个子模块,分别是:
样本的计算和处理
包组的延迟梯度
在WebRTC中,Trendline滤波器的样本为包组的延迟梯度值作。以下是包组的延迟梯度值的计算方式:
1
2// 包组的延迟梯度 = 包组的抵达时间间隔 - 发送时间间隔的差值
propagation delay = inter-arrival - inter-departure关于包组的发送时间间隔和抵达时间间隔的计算,可参考文章 WebRTC之包组的时间间隔 。
一次指数平滑法
由于网络拥塞以及包组划分方式等原因,包组的延迟梯度值或多或少存在一些误差,因此需要对其进行平滑处理。
在WebRTC中,使用的是一次指数平滑法,其本质上也是一种加权的平均算法。关于一次指数平滑法的介绍,可参考文章 时序模型初探之三:指数平滑法 。
一次指数平滑算法特点在于:加权系数是随着时间呈指数变化,且距离现在越远的样本对应的系数越小,这也是其名字的由来。一次指数平滑法兼容了所有样本对未来值的影响,且符合历史样本对未来值的影响是随着时间地推移而递减的客观规律。
以下是一次指数平滑公式:
其中,\hat{y}_{t+1}为未来预测值,
为当前预测值, 为当前样本值, 为加权系数,且: 。 关于加权系数
的选取建议是: - 如果时间序列波动不大,则
的值应取小一点,e.g. 0.1~0.5之间 - 如果时间序列具有迅速且明显的变动倾向,则
的值应取大一点,e.g. 0.6~0.8之间。这样预测模型更为灵敏,以便迅速响应变化。
在WebRTC中,
的默认值为0.9,换言之, 的取值为0.1。 - 如果时间序列波动不大,则
代码导读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68void TrendlineEstimator::UpdateTrendline(double recv_delta_ms,
double send_delta_ms,
int64_t send_time_ms,
int64_t arrival_time_ms,
size_t packet_size) {
// 传输延迟
const double delta_ms = recv_delta_ms - send_delta_ms;
// 统计样本个数
++num_of_deltas_;
// 限定样本个数
num_of_deltas_ = std::min(num_of_deltas_, kDeltaCounterMax);
// 首个包的抵达时间,作为样本计算相对抵达时间的参考点
if (first_arrival_time_ms_ == -1)
first_arrival_time_ms_ = arrival_time_ms;
// Exponential backoff filter.
// 累积的延迟值
accumulated_delay_ += delta_ms;
BWE_TEST_LOGGING_PLOT(1, "accumulated_delay_ms", arrival_time_ms,
accumulated_delay_);
// 计算延迟一次指数平滑值
smoothed_delay_ = smoothing_coef_ * smoothed_delay_ +
(1 - smoothing_coef_) * accumulated_delay_;
BWE_TEST_LOGGING_PLOT(1, "smoothed_delay_ms", arrival_time_ms,
smoothed_delay_);
// Maintain packet window
// 相对抵达时间和累积的延迟平滑值分别作为线性回归样本的x和y值
delay_hist_.emplace_back(
static_cast<double>(arrival_time_ms - first_arrival_time_ms_),
smoothed_delay_, accumulated_delay_);
// 最小二乘法的样本按抵达时间排序
if (settings_.enable_sort) {
for (size_t i = delay_hist_.size() - 1;
i > 0 &&
delay_hist_[i].arrival_time_ms < delay_hist_[i - 1].arrival_time_ms;
--i) {
std::swap(delay_hist_[i], delay_hist_[i - 1]);
}
}
// 由于只需要关注近期的斜率变化趋势,因此使用滑动窗口过滤掉历史数据的影响
if (delay_hist_.size() > settings_.window_size)
delay_hist_.pop_front();
// Simple linear regression.
double trend = prev_trend_;
// 使用最小二乘法求拟合函数
if (delay_hist_.size() == settings_.window_size) {
// Update trend_ if it is possible to fit a line to the data. The delay
// trend can be seen as an estimate of (send_rate - capacity)/capacity.
// 0 < trend < 1 -> the delay increases, queues are filling up
// trend == 0 -> the delay does not change
// trend < 0 -> the delay decreases, queues are being emptied
trend = LinearFitSlope(delay_hist_).value_or(trend);
// 限定延时梯度斜率值
if (settings_.enable_cap) {
absl::optional<double> cap = ComputeSlopeCap(delay_hist_, settings_);
// We only use the cap to filter out overuse detections, not
// to detect additional underuses.
if (trend >= 0 && cap.has_value() && trend > cap.value()) {
trend = cap.value();
}
}
}
BWE_TEST_LOGGING_PLOT(1, "trendline_slope", arrival_time_ms, trend);
// 带宽状态检测
Detect(trend, send_delta_ms, arrival_time_ms);
}
基于线性回归求延迟的拟合函数
由于一次指数平滑法只适用于时间序列没有明显变化趋势的场景,但是包组的延迟梯度会随着网络拥塞程度的变化而出现某种线性变化。因此,如果仅用一次平滑法预测的未来值会存在明显的滞后偏差。因此,我们需要建立线性趋势模型进行修正。在WebRTC中,采用最小二乘法来建立线性趋势模型。
最小二乘法
最小二乘法,是一种基于线性回归求拟合函数的方法,它通过寻找误差的平方和的最小值来获得最接近真实情况的线性函数,所谓”二乘“就是平方的意思。以下是其数学推导过程:
假设线性关系函数为,其中a为斜率,b为截距:
对于任意样本点
,误差值为: 总误差的平方为:
分别求a和b的一阶偏导数:
根据极值定理,当a和b的一阶偏导数为0时原函数存在极值点。再分别求a和b的二阶导数:
由于a的二阶偏导数是一个凹函数,b的二阶偏导数是一个正数,因此,极值点为最小值,即误差值最小。令a和b的一阶偏导数为0,最终可推导出关于a和b的函数:
其中,
和 分别表示x和y的算术平均值。
NOTE:由于误差是随机且独立的,即误差的分布符合正态分布。根据中心极限定量,当误差最小时,使用最小二乘法进行线性回归求得拟合函数最接近真实情况。
延迟梯度变化的预测模型
在Trendline滤波器中,假设抵达时间和延迟梯度平滑值之间存在线性关系,其线性函数为:
1
2// 延迟梯度平滑值 = 斜率 * 相对于第一个包的抵达时间 + 截距
smoothed_delay_ms = k * relative_arrival_time_ms + b斜率k值表示延迟的变化趋势,分以下三种情况:
- 0 < k < 1:表示数据包的延迟正在变大,路由器的缓存队列处于不断地增加的趋势,直到整个网络缓冲区被填满为止。
- k == 0:表示数据包的延迟无变化,即路由器的缓存队列长度无变化。
- k < 0:表示数据包的延迟正在变小,即路由器的缓冲队列处于不断地减少的趋势,直到整个网络缓冲区被清空为止。
代码导读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 求线性函数的斜率值
absl::optional<double> LinearFitSlope(
const std::deque<TrendlineEstimator::PacketTiming>& packets) {
RTC_DCHECK(packets.size() >= 2);
// Compute the "center of mass".
// x:表示相对抵达时间
// y:表示延迟平滑值
double sum_x = 0;
double sum_y = 0;
// 计算当前窗口下,x和y的总和
for (const auto& packet : packets) {
sum_x += packet.arrival_time_ms;
sum_y += packet.smoothed_delay_ms;
}
// 计算算术平均值
double x_avg = sum_x / packets.size();
double y_avg = sum_y / packets.size();
// 计算斜率k的值
// Compute the slope k = \sum (x_i-x_avg)(y_i-y_avg) / \sum (x_i-x_avg)^2
double numerator = 0;
double denominator = 0;
for (const auto& packet : packets) {
double x = packet.arrival_time_ms;
double y = packet.smoothed_delay_ms;
numerator += (x - x_avg) * (y - y_avg);
denominator += (x - x_avg) * (x - x_avg);
}
if (denominator == 0)
return absl::nullopt;
return numerator / denominator;
}
带宽过载检测
在WebRTC中,带宽评估有三个状态值,分别是:
1
2
3
4
5enum class BandwidthUsage {
kBwNormal = 0, // 正常状态
kBwUnderusing = 1, // 低载状态
kBwOverusing = 2, // 过载状态
};这三种状态的切换是基于延迟梯度斜率值与阈值的比较,以下是状态切换图:
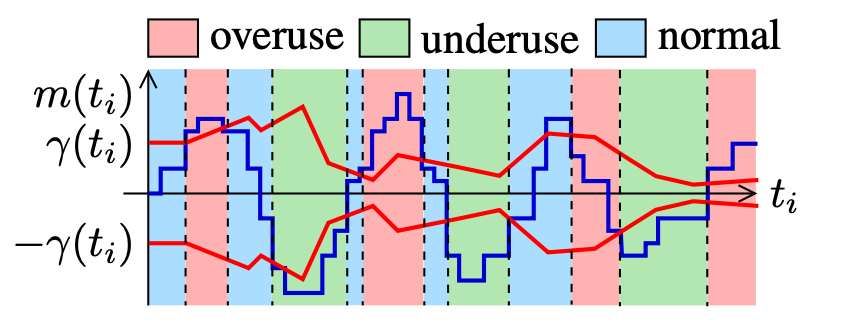
其中,
表示修正后梯度延迟梯度斜率值,即图中的蓝色曲线, 表示自适应阈值,即图中的两条红色曲线。带宽状态切换条件: 优化处理
在检测带宽状态时,并不是简单地将延迟梯度的斜率值与固定的阈值进行比较,从而获得带宽评估的状态值。因此这种直接比较的方式会导致评估结果对于延迟梯度的变化过于敏感,实际上,在具体实现时进行加入了以下优化处理:
修正延迟梯度的斜率值
本质上是将斜率值的波动范围变大,修正公式如下:
1
2// 修正后的斜率值 = 样本数 * 修正前的斜率值 * 阈值增益
double modified_trend = min(num_of_samples, 60) * trend * threshold_gain关于这个公式背后的原理还尚未弄明白,我目前的理解是:
由于threshold_gain是一个定值,所以当样本数小于60时,影响修正结果的是样本数和斜率值本身,此后唯一的变量则只有斜率值。因此,修正可以理解为就是对斜率值的一次增益处理,且增益值除起始阶段外就是一个定值。
增益值的大小决定了自适应阈值的取值范围,因为阈值的自适应算法是基于修正后的趋势值进行自适应更新的。
加入额外的过载触发条件
带宽过载的触发条件除了修正后的斜率值大于当前阈值,还加入了以下三个额外的条件:
- 时间上:过载维持时长大于10ms
- 次数上:过载次数超过1次
- 趋势上:当前延迟梯度斜率值(未修正)大于上一次的斜率值,即延迟在持续增加
使用自适应的阈值
使用自适应阈值的原因,主要包括以下三个:
- 由于带宽检测相较于带宽变化是滞后的,即基于延迟的带宽评估算法的检测结果具有一定的滞后性,因此,基于该算法的带宽调整不宜过于灵敏。
- 使用固定的阈值,不能及时响应带宽变化,要么不够灵敏,要么过于灵敏。
- 由于TCP数据流采用的是基于丢包的带宽评估算法,这是一种贪婪算法,在丢包率低时会不断地增加码率。因此,如果GCC中基于延迟的带宽评估算法过于灵敏,即一旦检测出带宽过载就立即开始降低码率,最终可能会导致GCC数据流一直处于低码率状态,即处于饥饿状态。
阈值的自适应算法,本质是一次指数平滑法,其特点在于加权系数的计算,分别是增益系数k和距离上次更新的时间间隔。其中,增益系数k的取值公式为:
其中,
表示当前的增益系数值, 表示修正后的趋势值, 表示上一次的阈值, 和 分别表示阈值范围缩小和扩大的速度,WebRTC中的取值分别是0.039和0.0087。 增益系数k的取值逻辑为:
- 当修正后的势趋值的波动处于阈值范围内,说明当前的阈值范围过大,需适当缩小。
- 当修正后的趋势值的波动超出阈值的范围,说明当前的阈值范围过小,需适当扩大。
自适应算法的一次指数平滑公式:
其中,
表示更新后的阈值, 表示上一次阈值, 表示距离上一次更新的时间间隔, 表示当前的增益系数k。
代码导读
过载检测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51void TrendlineEstimator::Detect(double trend, double ts_delta, int64_t now_ms) {
// 样本个数少于2个时,趋势值的拟合度太低
if (num_of_deltas_ < 2) {
// 视为起始阶段的状态
hypothesis_ = BandwidthUsage::kBwNormal;
return;
}
// 对趋势值进行修正处理
const double modified_trend =
std::min(num_of_deltas_, kMinNumDeltas) * trend * threshold_gain_;
prev_modified_trend_ = modified_trend;
BWE_TEST_LOGGING_PLOT(1, "T", now_ms, modified_trend);
BWE_TEST_LOGGING_PLOT(1, "threshold", now_ms, threshold_);
// 基于修正后的趋势值和自适应阈值进行带宽评估
if (modified_trend > threshold_) {
// 带宽过载
// 统计过载时长
if (time_over_using_ == -1) {
// Initialize the timer. Assume that we've been
// over-using half of the time since the previous
// sample.
time_over_using_ = ts_delta / 2;
} else {
// Increment timer
time_over_using_ += ts_delta;
}
// 统计过载次数
overuse_counter_++;
// 额外的三个过载触发条件,同时满足才更新带宽状态为过载状态
if (time_over_using_ > overusing_time_threshold_ && overuse_counter_ > 1) {
if (trend >= prev_trend_) {
time_over_using_ = 0;
overuse_counter_ = 0;
hypothesis_ = BandwidthUsage::kBwOverusing;
}
}
} else if (modified_trend < -threshold_) {
// 带宽处于低载状态
time_over_using_ = -1;
overuse_counter_ = 0;
hypothesis_ = BandwidthUsage::kBwUnderusing;
} else {
// 带宽处于正常状态
time_over_using_ = -1;
overuse_counter_ = 0;
hypothesis_ = BandwidthUsage::kBwNormal;
}
prev_trend_ = trend;
// 更新自适应阈值
UpdateThreshold(modified_trend, now_ms);
}更新自适应阈值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28void TrendlineEstimator::UpdateThreshold(double modified_trend,
int64_t now_ms) {
// 记录此次更新时间。
if (last_update_ms_ == -1)
last_update_ms_ = now_ms;
// 过滤延迟峰值
if (fabs(modified_trend) > threshold_ + kMaxAdaptOffsetMs) {
// 由于峰值一般都是突发的,避免对其进行自适应更新,确保阈值维持在一个合理范围。
// Avoid adapting the threshold to big latency spikes, caused e.g.,
// by a sudden capacity drop.
// 阈值不更新,可理解为维持原值,所以仍视为一次更新操作。
last_update_ms_ = now_ms;
return;
}
// 计算增益系数k
const double k = fabs(modified_trend) < threshold_ ? k_down_ : k_up_;
const int64_t kMaxTimeDeltaMs = 100;
// 计算距离上一次更新的时间间隔
int64_t time_delta_ms = std::min(now_ms - last_update_ms_, kMaxTimeDeltaMs);
// 采用一次指数平滑法更新阈值
threshold_ += k * (fabs(modified_trend) - threshold_) * time_delta_ms;
// 确保修正后的阈值在一个合理的范围
threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f);
// 记录此次更新时间
last_update_ms_ = now_ms;
}